実行プランのスキーマを見る機会があったので、久々に blog を…。
ここから xsd をダウンロードできます。
Showplan Schema
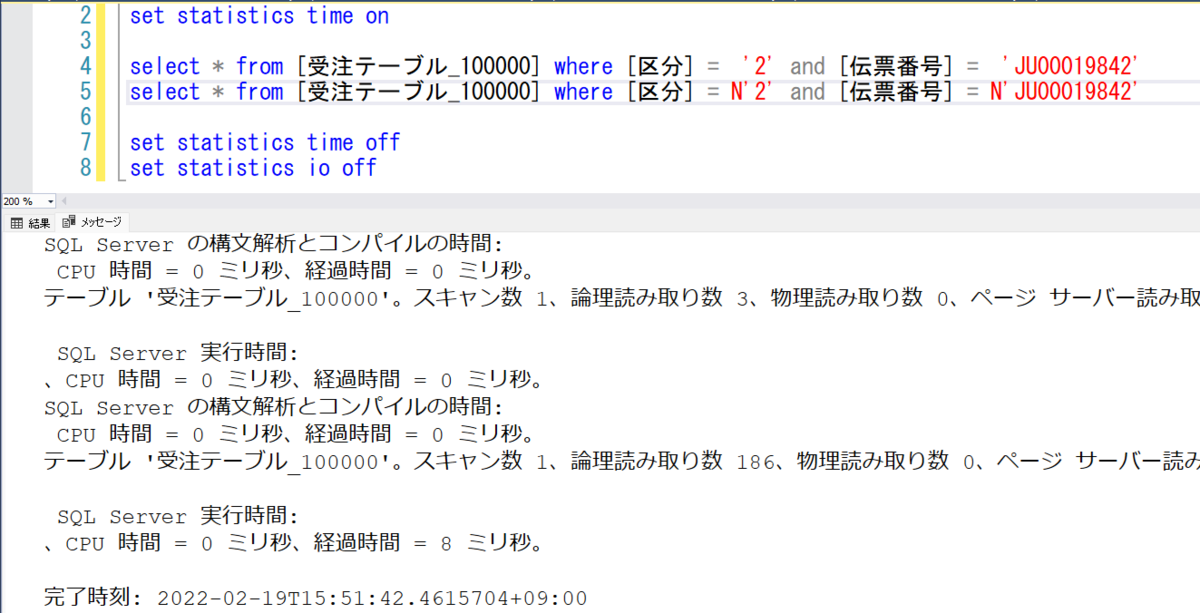
単純に diff を取ると、2019 では、PDW や Spill、UDF、Page Server 等の情報が詳しく取れるようになってました。
サクッと検証出来る UDF で見てみましょう。
<xsd:complexType name="QueryExecTimeType"> <xsd:annotation> <xsd:documentation> Shows time statistics for single query execution. CpuTime: CPU time in milliseconds ElapsedTime: elapsed time in milliseconds UdfCpuTime: Cpu time of UDF in milliseconds UdfElapsedTime: Elapsed time of UDF in milliseconds </xsd:documentation> </xsd:annotation> <xsd:attribute name="CpuTime" type="xsd:unsignedLong" use="required" /> <xsd:attribute name="ElapsedTime" type="xsd:unsignedLong" use="required" /> <xsd:attribute name="UdfCpuTime" type="xsd:unsignedLong" use="optional" /> <xsd:attribute name="UdfElapsedTime" type="xsd:unsignedLong" use="optional" /> </xsd:complexType>
UDF (ユーザー定義関数) の CPU 時間と経過時間が追加されていました。
という訳で、次のような関数を作って、それぞれ実行プランを取ってみます。
create function dbo.SlowUdf() returns int as begin declare @r int; with cte as ( select 1 as seq union all select seq + 1 from cte where seq < 100000 ) select top(1) @r = seq from cte order by seq desc option (maxrecursion 0) return @r end go create function dbo.FastUdf() returns int as begin return 0 end go
select dbo.SlowUdf()
の実行プランから該当部分を抜粋すると、
<QueryPlan DegreeOfParallelism="0" NonParallelPlanReason="CouldNotGenerateValidParallelPlan" CachedPlanSize="16" CompileTime="0" CompileCPU="0" CompileMemory="72"> ...<省略> <QueryTimeStats CpuTime="530" ElapsedTime="721" UdfCpuTime="530" UdfElapsedTime="721" /> ...<省略>
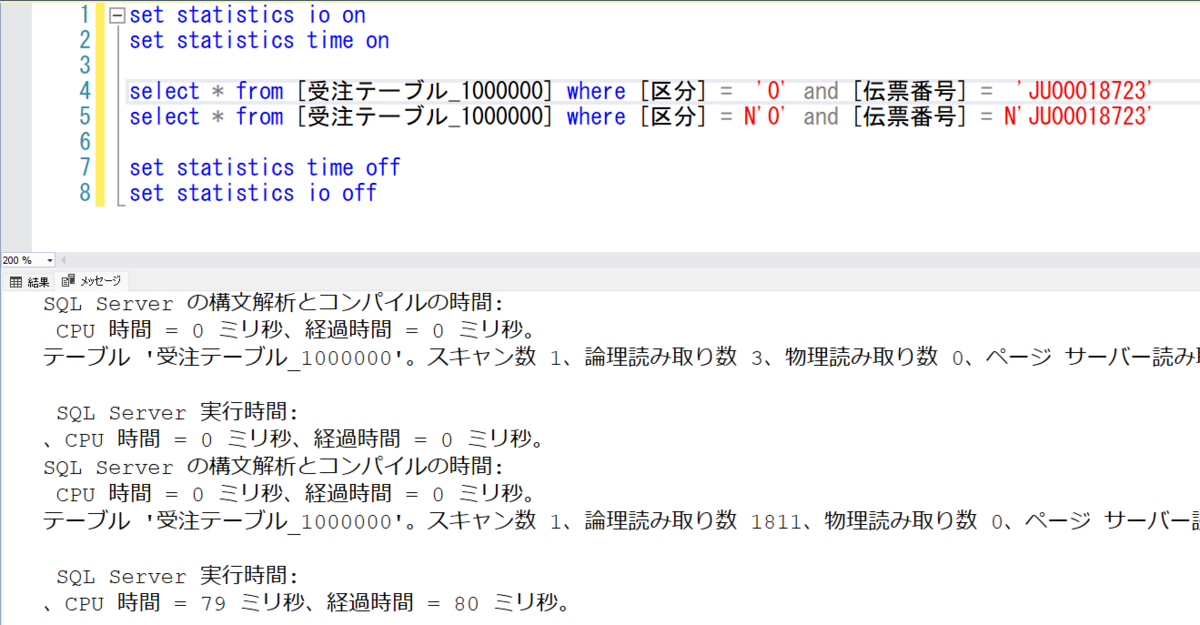
select dbo.FastUdf()
の実行プランから該当部分を抜粋すると、
<QueryPlan DegreeOfParallelism="1" CachedPlanSize="16" CompileTime="0" CompileCPU="0" CompileMemory="80" ContainsInlineScalarTsqlUdfs="true"> ...<省略> <QueryTimeStats CpuTime="0" ElapsedTime="0" /> ...<省略>
SlowUdf は、UdfCpuTime、UdfElapsedTime が追加されています。
FastUdf は、UdfCpuTime、UdfElapsedTime が 0なのでしょう、省略されています。*1
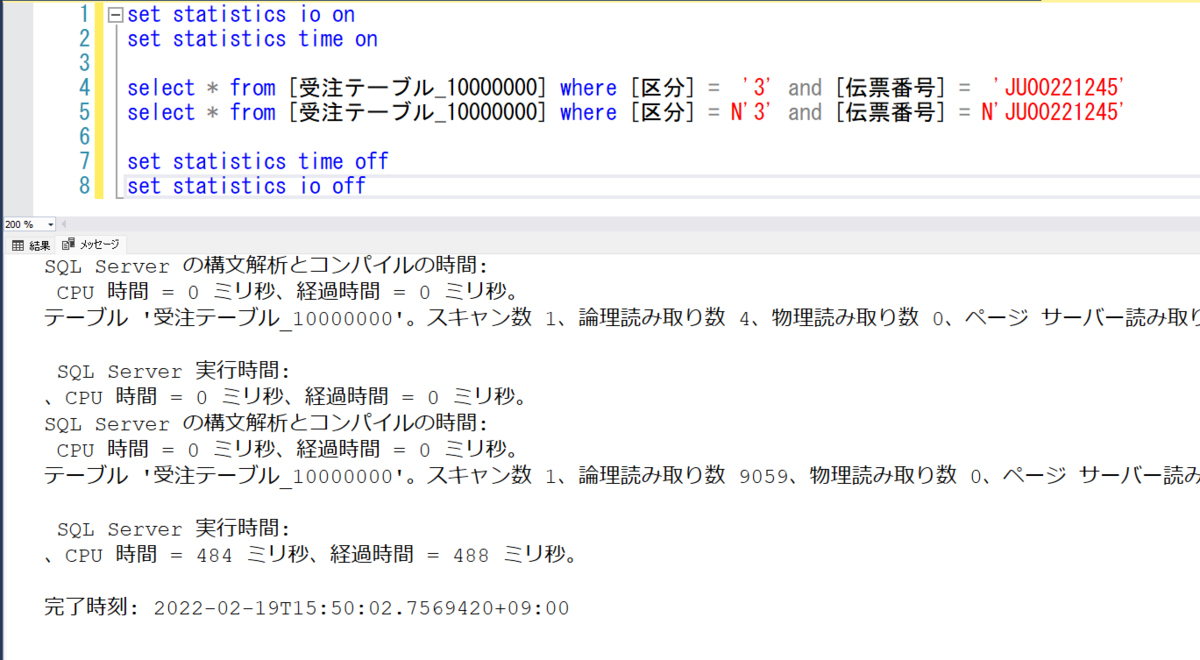
同じ内容を 2017 で実行すると、 SlowUdf()
<QueryPlan DegreeOfParallelism="0" NonParallelPlanReason="CouldNotGenerateValidParallelPlan" CachedPlanSize="16" CompileTime="0" CompileCPU="0" CompileMemory="72"> ...<省略> <QueryTimeStats CpuTime="505" ElapsedTime="697" /> ...<省略>
FastUdf()
<QueryPlan DegreeOfParallelism="0" NonParallelPlanReason="CouldNotGenerateValidParallelPlan" CachedPlanSize="16" CompileTime="0" CompileCPU="0" CompileMemory="72"> ...<省略> <QueryTimeStats CpuTime="0" ElapsedTime="0" /> ...<省略>
UDF の情報はありませんね!
ちなみに 2016 => 2016sp1 では、クエリ中のWaitStats(待ち事象)が取れるようになってました。
知らないうちに色々増えているので確認しとかないとダメっすねー。
*1:use="optional"