この記事は meetup app osaka@6 - connpass の参加記事です。
試した環境:SQL Server 2019 15.0.2080.9
型を合わせてないと、起きる問題の1パターンを紹介します。
今回は、文字列型の char, varchar / nchar, nvarchar 間の話しです。
比較用のテーブルとデータは、同じ構造で 1万件、10万件、100万件、1000万件 と用意しました。
drop table if exists 受注テーブル_10000 drop table if exists 受注テーブル_100000 drop table if exists 受注テーブル_1000000 drop table if exists 受注テーブル_10000000 create table [受注テーブル_10000] ( [Id] bigint not null primary key , [区分] char(1) not null , [伝票番号] varchar(10) not null , index [IX_10000_区分_伝票番号] ([区分], [伝票番号]) ) create table [受注テーブル_100000] ( [Id] bigint not null primary key , [区分] char(1) not null , [伝票番号] varchar(10) not null , index [IX_100000_区分_伝票番号] ([区分], [伝票番号]) ) create table [受注テーブル_1000000] ( [Id] bigint not null primary key , [区分] char(1) not null , [伝票番号] varchar(10) not null , index [IX_1000000_区分_伝票番号] ([区分], [伝票番号]) ) create table [受注テーブル_10000000] ( [Id] bigint not null primary key , [区分] char(1) not null , [伝票番号] varchar(10) not null , index [IX_10000000_区分_伝票番号] ([区分], [伝票番号]) ) go with [cte] as (select 1 as [cnt] union all select [cnt] + 1 from [cte] where [cnt] < 10000) insert into [受注テーブル_10000] ([Id], [区分], [伝票番号]) select [cnt], cast(([cnt] % 4) as char(1)), concat('JU', format([cnt] / 4, N'D8')) from [cte] option (maxrecursion 0) ; with [cte] as (select 1 as [cnt] union all select [cnt] + 1 from [cte] where [cnt] < 100000) insert into [受注テーブル_100000] ([Id], [区分], [伝票番号]) select [cnt], cast(([cnt] % 4) as char(1)), concat('JU', format([cnt] / 4, N'D8')) from [cte] option (maxrecursion 0) ; with [cte] as (select 1 as [cnt] union all select [cnt] + 1 from [cte] where [cnt] < 1000000) insert into [受注テーブル_1000000] ([Id], [区分], [伝票番号]) select [cnt], cast(([cnt] % 4) as char(1)), concat('JU', format([cnt] / 4, N'D8')) from [cte] option (maxrecursion 0) ; with [cte] as (select 1 as [cnt] union all select [cnt] + 1 from [cte] where [cnt] < 10000000) insert into [受注テーブル_10000000] ([Id], [区分], [伝票番号]) select [cnt], cast(([cnt] % 4) as char(1)), concat('JU', format([cnt] / 4, N'D8')) from [cte] option (maxrecursion 0) ;
それぞれのテーブルで、[区分]、[伝票番号] に対して、1件に絞るクエリを varchar 型 と nvarchar 型 の2パターンの実行計画を見比べます。
取り合えず1万件のテーブルで実行計画を比較してみましょう。
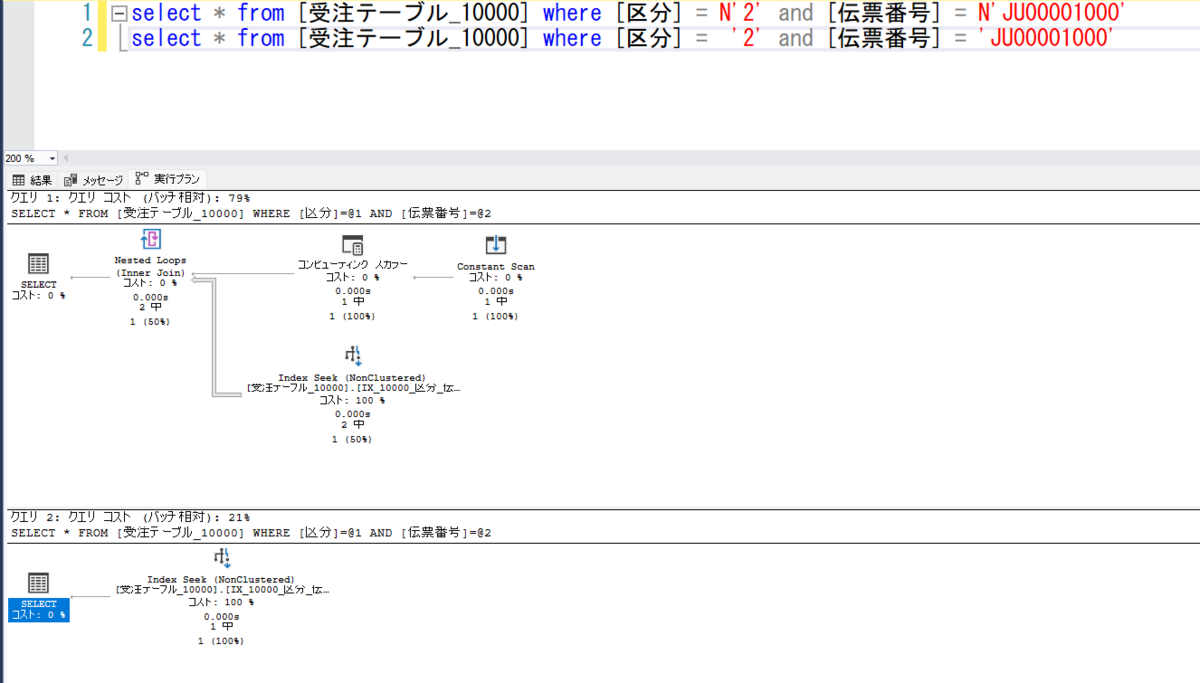
nvarchar で渡してる方は何かややこしいことになってのが分かります。
Index Seek の詳細の詳細を見ると…
varchar
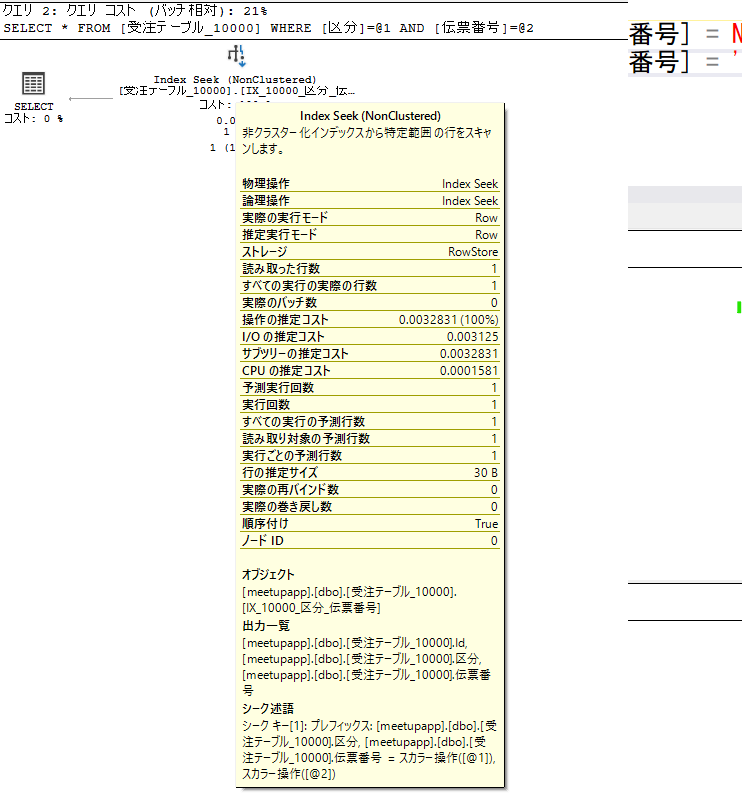
シーク述語を見ると、普通に [区分]、[伝票番号] に対して条件を比較している。
nvarchar

こっちは、述語を見ると、
CONVERT_IMPLICIT(nchar(1),[meetupapp].[dbo].[受注テーブル_10000].[区分],0)=[@1] AND CONVERT_IMPLICIT(nvarchar(10),[meetupapp].[dbo].[受注テーブル_10000].[伝票番号],0)=[@2]
とあり、型変換していることが分かる。
このままだと普通はインデックスが使われない(Seek ではなく、Scan になる)が、
SQL Server は頑張って、Seek になるようにしている。
※SQL Server 2012 では、Scan になっていた、2014 では 今と同じ動作。
シーク述語をみると、
開始: [meetupapp].[dbo].[受注テーブル_10000].[区分] > スカラー操作([Expr1005]) 終了: [meetupapp].[dbo].[受注テーブル_10000].[区分] < スカラー操作([Expr1006])
となっており、Seek にはなっているが、[区分] の範囲比較になっている。
実行計画を詳しくみると、GetRangeThroughConvert という like 検索でも使われる文字の範囲を取得すると思われる内部関数が使われている。
が、ここでは気にしない。
で、[区分] しか Seek に使っていないので、実行時に不利になってそう。
では、set statistics io と set statistics time で件数別で実行時の IO と 時間を確認してみる。
1万件
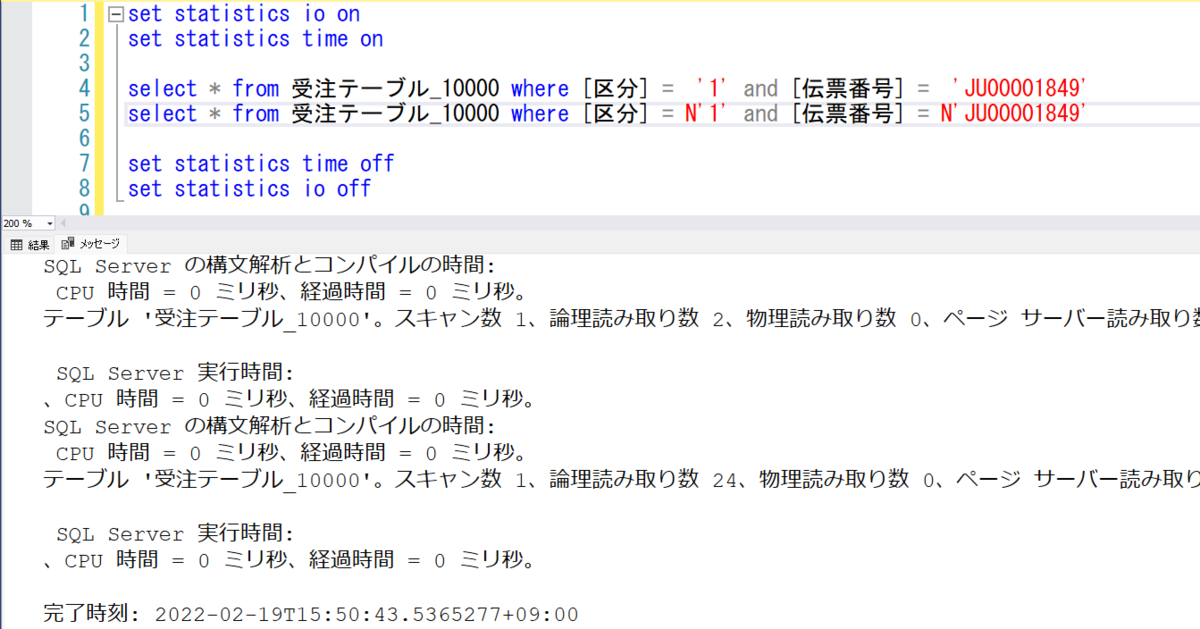
logical read(論理読み取り数) が 2 => 24 になってるが、elapsed time(経過時間) は 0 ms のまま。
10万件
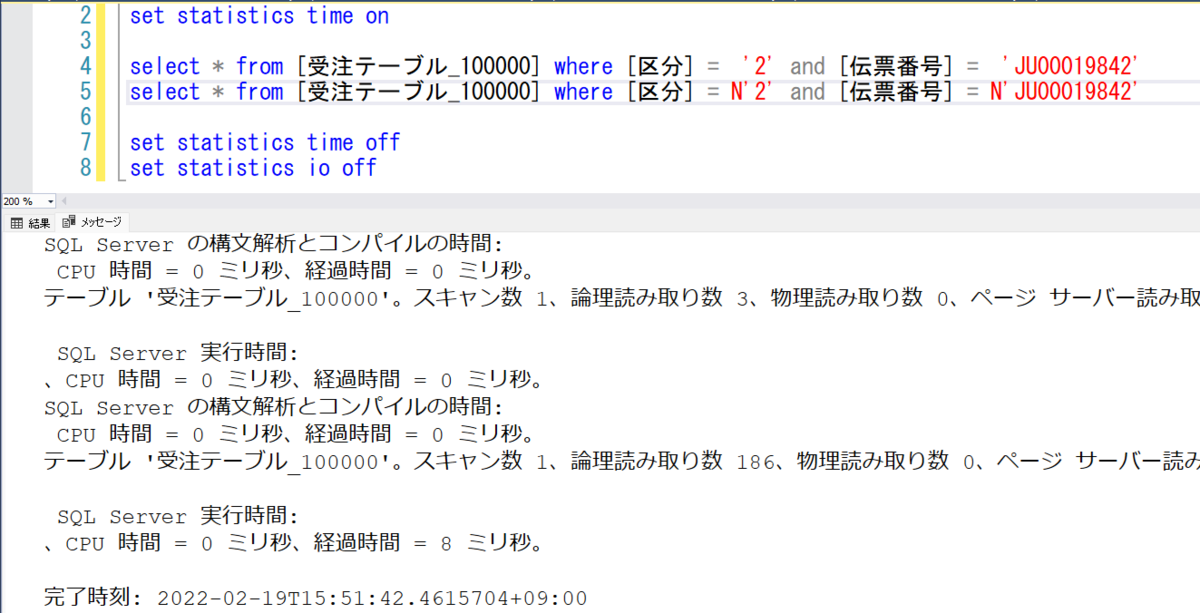
logical read(論理読み取り数) が 3 => 186 で、elapsed time(経過時間) は 0 ms => 8 ms
100万件
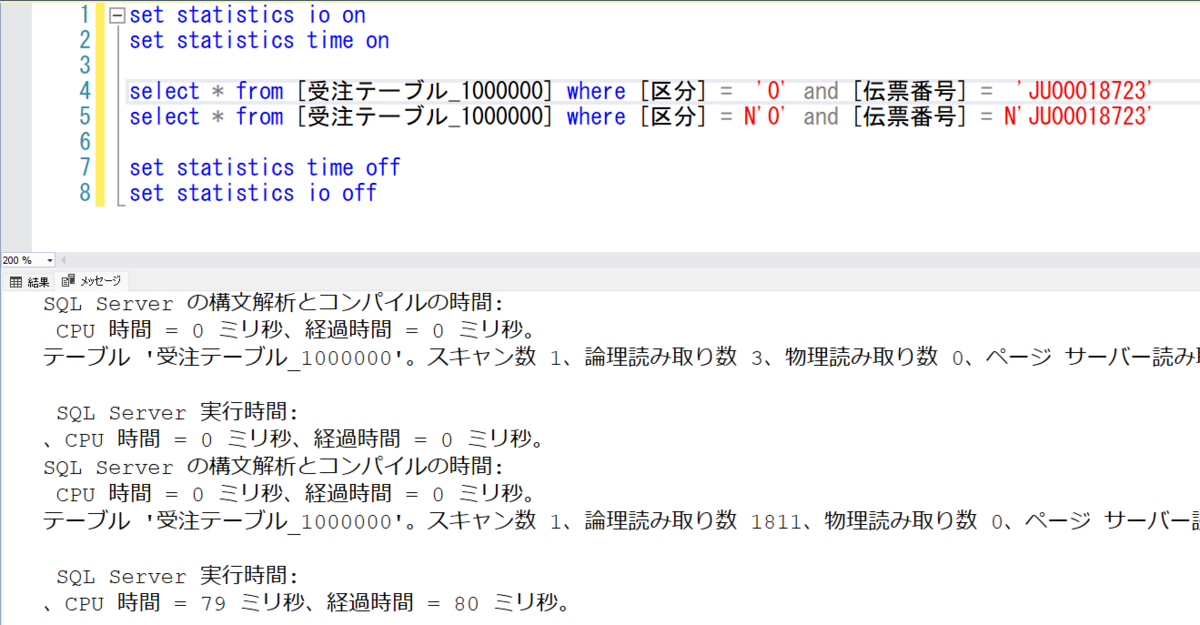
logical read(論理読み取り数) が 3 => 1811 で、elapsed time(経過時間) は 0 ms => 80 ms
1000万件
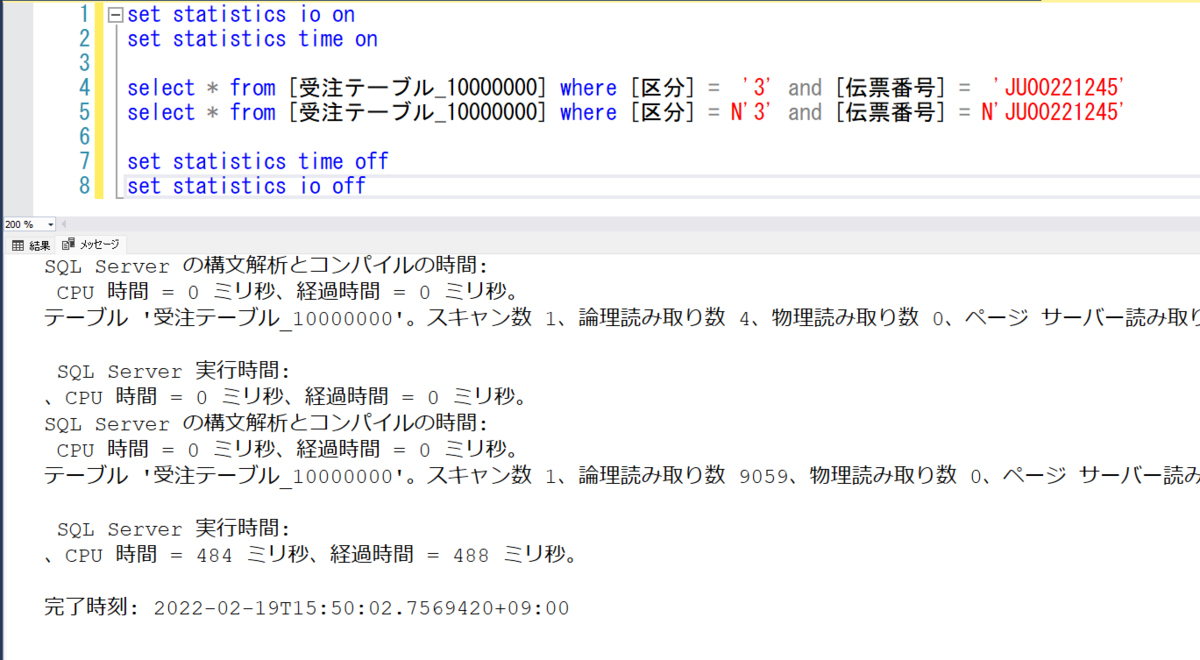
logical read(論理読み取り数) が 4 => 9059 で、elapsed time(経過時間) は 0 ms => 488 ms
件数が増えるにつれて、段々と遅くなっていくのが分かる。
インデックスを作って使ってるのに昔は速かったのに今は遅いというケースの1パターンに該当するのでは?
0.5秒って大したことないように見えてもこれが何万回も実行されるとちりも積もってで結構な差に…。
ちなみに、今回は複合インデックス(列が2個以上のインデックス)で比較したが、単一列のインデックスの場合は、
ここまで顕著に差は出ません。
※シーク述語 で、インデックスの最初の列を範囲検索しているので、単一列インデックスだと、その列しか無いため
今回は条件にリテラルで値を指定していますが、他にも
- テーブル間を join する時に、双方の列の型が違う
- プログラムから SQL を発行する際の変数の型を指定しなかったため、既定の動作で全部 nvarchar になった
等で同じことが起きます。
join するテーブルの列の型が違うのはそういうのの担当の人に相談するとして、
実装する人は、プログラムから SQL 呼び出すときに変数の型を手抜きしない、
クエリのリテラルに気を付けてると、何年か経ったときに遅くなって困ってるっていう相談を聞かずに済むかも?
*1:うちの環境で6分近く掛かった。