決められた範囲があって、その中で空いている最小の番号を取得するってクエリ。
例:40000~4000000 までの間で未使用の番号を少ない順に10個とる。
範囲用の表を作って存在しないデータ取得
with [範囲] as (
select cast(40000 as bigint) as [番号]
union all
select [番号] + 1 from [範囲] where [番号] < 4000000
), [使用済] as (
select [番号] from
(values (40001), (40003), (40004),
(40005), (40008), (40009), (40010)) as [t]([番号])
)
select top(10) [範囲].[番号]
from [範囲]
where not exists (
select * from [使用済]
where [使用済].[番号] = [範囲].[番号]
)
option (maxrecursion 0)
結果はこんなん
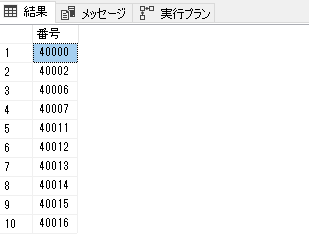
実行プランを見ると、Nested Loops の 後に Top なので、サクッと終わる。
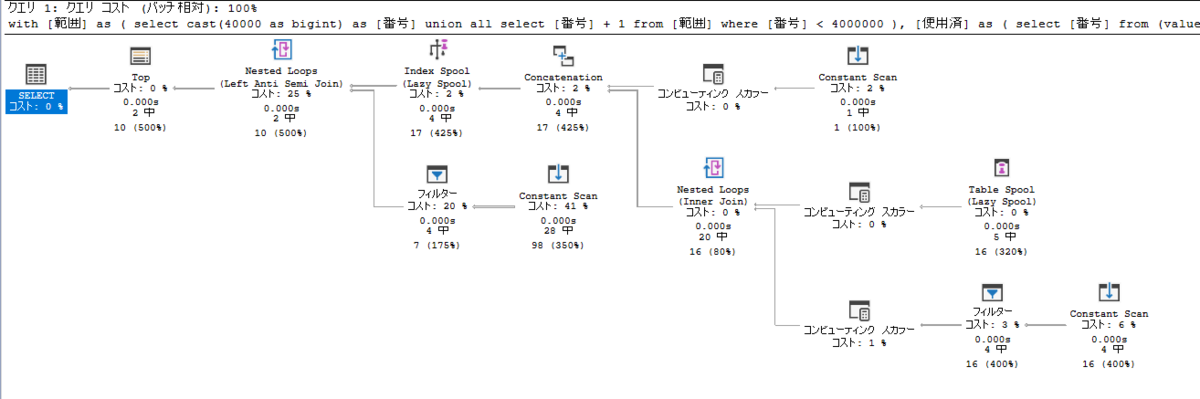
これ option (maxrecursion 0) してるけど、実際には、10件取れるまでしかループしてないから、無くてもエラーにならない。
再帰クエリで循環参照した時にどうなるのか?(SQL Server, PostgreSQL) - お だ のスペース
で少し書いたけど、再帰クエリと Top 良い感じ。
データ増えるとどうなるかというと…
drop table if exists [使用済]
create table [使用済] (
[番号] bigint
);
with cte as (
select cast(40002 as bigint) as [番号]
union all
select [番号] + 1 from [cte] where [番号] < 3999900
)
insert into [使用済] select [番号] from cte
option (maxrecursion 0)
;
insert into [使用済] values (3999905), (3999906), (3999910)
;
with [範囲] as (
select cast(40000 as bigint) as [番号]
union all
select [番号] + 1 from [範囲] where [番号] < 4000000
)
select top(10) [範囲].[番号]
from [範囲]
where not exists (
select * from [使用済]
where [使用済].[番号] = [範囲].[番号]
)
option (maxrecursion 0)
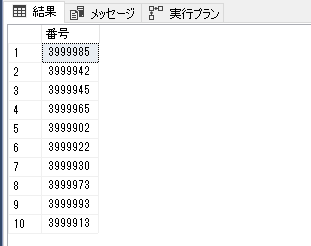
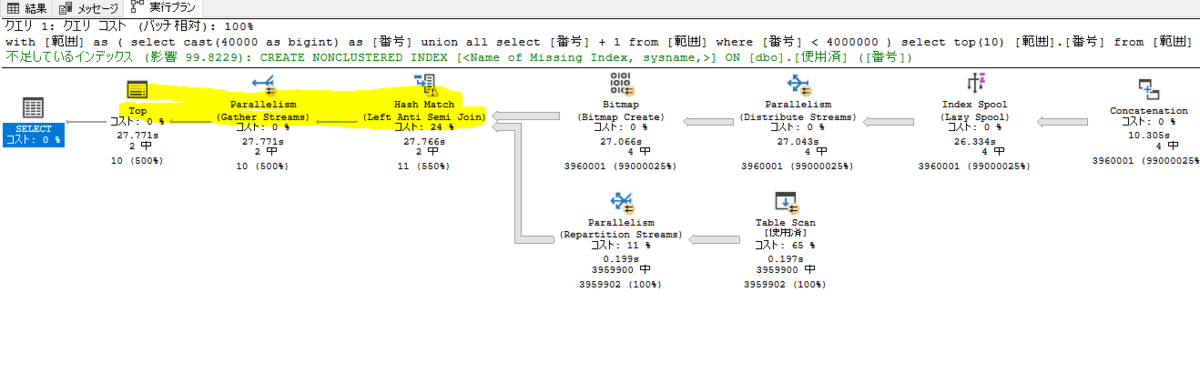
めっちゃ遅いし、40000, 40001 が入ってない。。
実行プランを見ると、Nested Loop じゃなくなったので、当然結果も違う。
ってことは order by を付けないとダメなんで件数少なくても全件ループしてしまうのでこのやり方じゃダメ。*1
※order by 付けなくてもこのデータ量だと、再帰のループが多すぎて遅すぎる!
ってことで、別のやり方を。
2021/08/20 追記 範囲用のテーブルが事前にあったら?
Twitter でレスあったので試しましたが、
事前に範囲用のテーブルがあった場合は、挙げたケースの中では一番早いかな。
↑のが遅いのは再帰の回数多くてデータ作るところが問題な訳で、元からデータがあったら問題無し。
drop table if exists [範囲]
;
create table [範囲] (
[番号] bigint not null primary key
)
;
with cte as (
select cast(40000 as bigint) as [番号]
union all
select [番号] + 1 from cte where [番号] < 4000000
)
insert into [範囲] select [番号] from cte
option (maxrecursion 0)
select top(10) [範囲].[番号]
from [範囲]
where not exists (
select * from [使用済]
where [使用済].[番号] = [範囲].[番号]
)
option (maxrecursion 0)
範囲が可変の場合に、どこまで事前に持たせるかってのは考え所ではあるかな~。
window 関数使って前後のデータと比較する
正直、クエリだけでやるのは大変なので、
クエリで空き番を取得するための材料を取る方向に逃げます。
LEAD (Transact-SQL) - SQL Server | Microsoft Docs と LAG (Transact-SQL) - SQL Server | Microsoft Docs を使って
select top(11) * from (
select [番号]
, lag([番号]) over (order by [番号]) as [前の番号]
, lead([番号]) over (order by [番号]) as [次の番号]
from [使用済]
) data_
where [番号] + 1 <> [次の番号]
or [次の番号] is null
or [前の番号] is null
order by [番号]
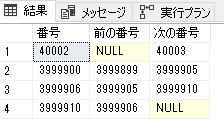
さっきよりは大分マシだけど、試した環境で 6秒位掛かるのでやっぱ待てないかな?
空き番取得 + 先頭 + 最後
1クエリで取るの諦めて、空き番取るだけ + 先頭 + 最後だと
select [空き開始番号], [空き終了番号]
from (
select [使用済].[番号] + 1 as [空き開始番号]
, (
select min([番号]) - 1
from [使用済] as [nest_]
where [nest_].[番号] > [使用済].[番号]
) as [空き終了番号]
from [使用済] left join [使用済] as [cond_]
on [使用済].[番号] = [cond_].[番号] - 1
where [cond_].[番号] is null
) as [data_]
where [空き終了番号] is not null
order by 1;
;
select top(1) [番号] as [先頭]
from [使用済] order by [番号]
;
select top(1) [番号] as [最後]
from [使用済] order by [番号] desc
;
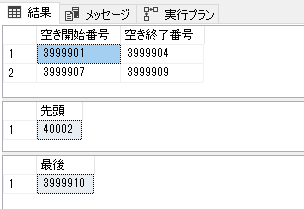
クエリ3つ発行するけどこれが一番良さげ。
データ件数とパフォーマンスと実装のしやすさで好きなの選んだらいーんじゃないかな?
ちなみに再帰で範囲データを作ってないやつは、範囲外のデータがある可能性があるので、範囲の条件を付ける必要あるよ!